
Securing AI Agents: Data Privacy Compliance & Encryption Framework
As AI agents become integral to business operations, protecting sensitive data through encryption, access controls, and compliance frameworks is essential.


Data Minimization and Collection Governance
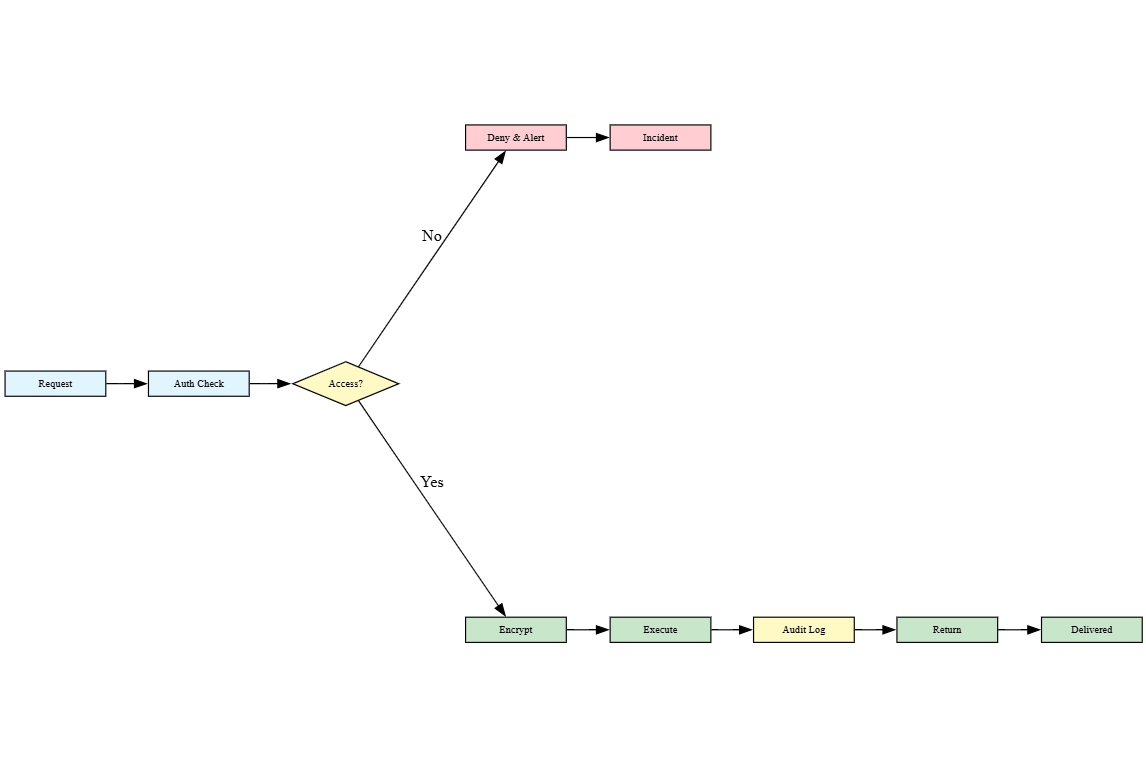
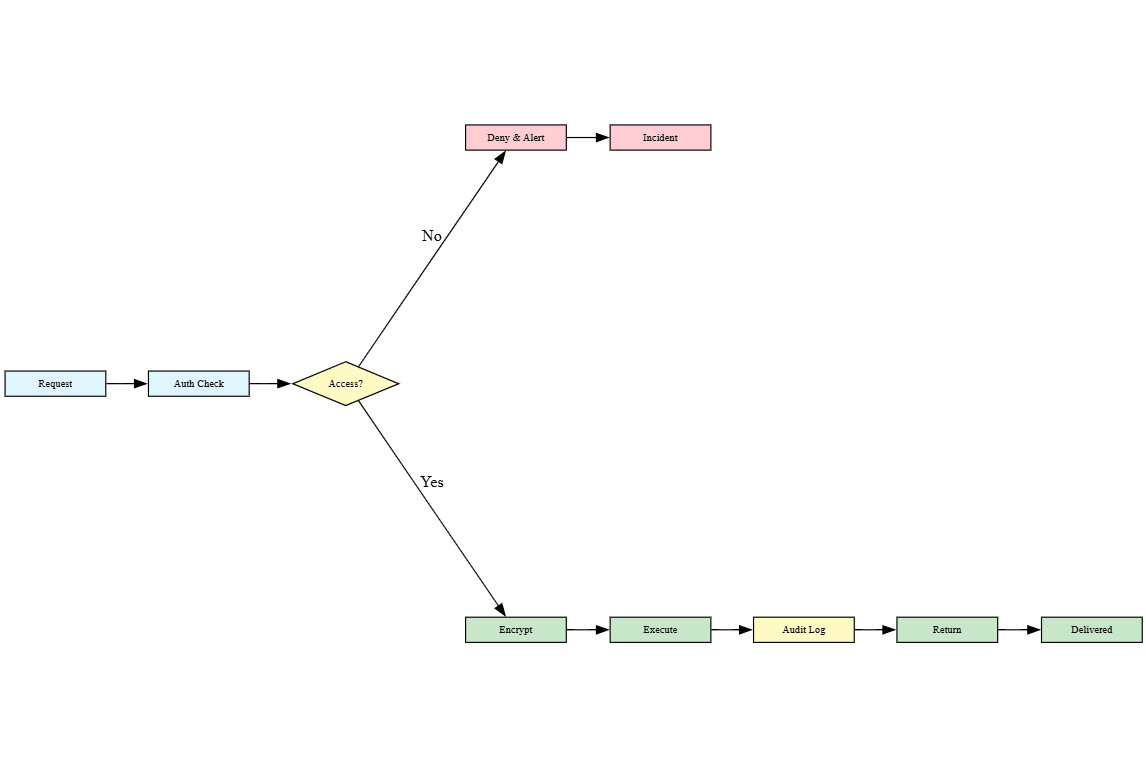
Implement principle-of-least-privilege data access: AI agents should only access datasets necessary for their specific tasks, reducing exposure surface and limiting potential breach impact by restricting unnecessary data permissions.
Establish data classification frameworks: Categorize information by sensitivity level (public, internal, confidential, restricted) to enforce differential protection policies and maintain comprehensive audit trails.
Encryption and Secure Communication
Deploy end-to-end encryption for agent communications: Encrypt data in transit between agents, services, and storage using TLS 1.3+ protocols to prevent man-in-the-middle attacks and ensure confidentiality.
Implement encryption at rest: Store sensitive data encrypted in databases and file systems using AES-256 encryption, ensuring that even if storage systems are compromised, data remains protected.
Model Security and Adversarial Robustness
Conduct adversarial testing and robustness evaluation: Regularly test AI agents against prompt injection attacks, data poisoning, and model extraction attempts to identify vulnerabilities before deployment.
Implement model versioning and integrity verification: Maintain cryptographic signatures for trained models to detect unauthorized modifications and ensure only authentic versions are deployed in production.
Attack Type Risk Level Mitigation Strategy Prompt Injection High Input validation, sandboxing, content filtering Data Poisoning High Data provenance tracking, validation checks Model Extraction Medium Rate limiting, output perturbation, access control Backdoor Attacks Critical Regular security audits, federated learning
Access Control and Authentication
Enforce role-based access control (RBAC) for agent operations: Define granular permissions specifying which agents can access specific data sources, APIs, or resources based on operational requirements.
Implement multi-factor authentication for agent initialization: Require cryptographic keys, biometric verification, or trusted third-party attestation before agents gain access to sensitive systems.
Audit Logging and Compliance
Maintain immutable audit trails of all agent activities: Log every data access, model decision, and external call with timestamps and contextual metadata for forensic analysis and regulatory compliance (GDPR, HIPAA, CCPA).
Enable real-time anomaly detection: Deploy monitoring systems to identify suspicious patterns such as unusual data volume requests or unauthorized API calls, triggering immediate incident response protocols.
Privacy-Preserving Machine Learning
Adopt differential privacy techniques: Add calibrated noise to training data or model outputs to maintain individual privacy guarantees while preserving aggregate model utility for business objectives.
Leverage federated learning architectures: Train models across distributed data sources without centralizing sensitive information, keeping raw data at origin while sharing only encrypted model updates.
Key Takeaways
Securing AI agents requires a defense-in-depth approach combining encryption, strict access controls, continuous monitoring, and privacy-first design principles. Organizations must treat agent security as an ongoing process rather than a one-time implementation, adapting protections as threat landscapes evolve. By prioritizing data minimization, encryption, and compliance frameworks, enterprises can deploy intelligent systems while maintaining robust privacy guardrails.
Frequently Asked Questions
Q1: How do AI agents handle personally identifiable information (PII) securely?
AI agents should implement data masking and tokenization techniques to minimize direct exposure to PII. Organizations can use synthetic data for testing, implement strict access controls limiting which agents can process PII, and ensure all PII-related operations are logged and monitored. Privacy-enhancing technologies like differential privacy ensure statistical analyses don’t reveal individual identities while maintaining data utility.
Q2: What are the main regulatory requirements for AI agent data privacy?
Key regulations include GDPR (General Data Protection Regulation) in Europe, CCPA (California Consumer Privacy Act), HIPAA for healthcare, and SOC 2 compliance. These frameworks require organizations to document data processing, obtain user consent, enable data portability, and implement security measures. AI agents must be designed to support data deletion requests, right-to-explanation requirements, and transparency in automated decision-making processes.
Q3: How can organizations detect if an AI agent has been compromised or tampered with?
Organizations should implement integrity verification mechanisms using cryptographic hashing of model weights, monitor model outputs for anomalies or drift, track model behavior changes, and maintain detailed versioning records. Regular security audits, penetration testing, and anomaly detection systems can identify unauthorized modifications. Unexpected performance degradation, increased false positives, or unusual data access patterns are red flags indicating potential compromise.
Q4: What’s the difference between federated learning and traditional centralized learning for privacy?
Traditional centralized learning requires collecting all data in one location before training, creating a single point of failure and privacy risk. Federated learning trains models on decentralized data sources, with each agent performing local computations and only sharing encrypted model updates. This approach keeps sensitive data at its origin, complies with data residency requirements, and reduces privacy exposure while achieving comparable model performance through aggregated learning.