
The Missing Piece in AI Agents: Why They're Useless Without Long-Term Memory
Understanding short-term vs. long-term memory in cognitive AI systems, and how to implement it for truly personalized interactions.


Introduction: The Goldfish Problem
Most AI agents today suffer from a form of digital amnesia. They can hold a coherent conversation within a single chat window, but once the session ends, they forget everything. They forget your preferences, your past requests, and the context you’ve built together. This is the “Goldfish Problem,” and it’s the primary barrier to creating AI that feels like a true collaborative partner, not just a sophisticated but forgetful tool.
The solution lies in architecting agents with a human-like memory system, comprising both Short-Term (Working) Memory and Long-Term Memory. This article breaks down the technical architecture and practical implementation of these systems.
1. Short-Term Memory: The Agent’s Conscious Mind
Short-Term Memory (STM) is the agent’s live workspace. It’s the context window of the Large Language Model (LLM), holding the immediate conversation history, the current task’s details, and any relevant data for the current interaction.
Technical Function: Manages the context window of the LLM, typically storing the last 4,000 to 200,000 tokens of the conversation.
Primary Role: Maintains coherence and state within a single session or task.
How It’s Implemented:
In frameworks like LangChain or LlamaIndex, STM is often managed automatically via the ConversationBufferWindowMemory or ConversationSummaryMemory classes.
python
from langchain.memory import ConversationBufferWindowMemory
# Keeps the last 5 exchanges in the context window
short_term_memory = ConversationBufferWindowMemory(k=5)
agent_chain = initialize_agent(
tools,
llm,
agent=AgentType.CONVERSATIONAL_REACT_DESCRIPTION,
memory=short_term_memory,
verbose=True
)Limitations of STM:
Limited Capacity: The context window is finite. Long conversations force the agent to “forget” the beginning.
Session-Bound: When the session ends, the memory is wiped clean.
No Personalization: The agent cannot learn from past interactions to improve future ones.
2. Long-Term Memory: The Agent’s Unconscious Knowledge
Long-Term Memory (LTM) is the agent’s persistent knowledge base. It’s where insights, user preferences, historical interactions, and learned facts are stored outside the LLM’s context window for later recall.
Technical Function: A vector database (e.g., Pinecone, Chroma) that stores “memories” as vector embeddings, allowing the agent to search for and retrieve relevant past information.
Primary Role: Enables learning, personalization, and continuity across multiple sessions.
How It’s Implemented:
LTM is typically built using a Retrieval-Augmented Generation (RAG) architecture. Experiences are chunked, converted into vectors, and stored. When a new query arrives, a semantic search finds the most relevant memories to inject into the context window.
python
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.schema import Document
# Initialize a vector store as long-term memory
vectorstore = Chroma(embedding_function=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()
def save_to_long_term_memory(user_id, conversation_summary):
“”“Saves a summarized memory to the vector database.”“”
memory_doc = Document(
page_content=f”User {user_id}: Prefers concise answers. Interested in {conversation_summary}.”,
metadata={”user_id”: user_id, “type”: “preference”}
)
vectorstore.add_documents([memory_doc])
def retrieve_memories(user_id, query):
“”“Retrieves relevant memories for a user based on the current query.”“”
return retriever.get_relevant_documents(f”User {user_id}: {query}”)3. The Complete Cognitive Architecture: STM + LTM
A sophisticated agent doesn’t use one or the other; it uses both in concert. The Long-Term Memory acts as a vast, searchable library, while the Short-Term Memory is the desk where the agent places the most relevant books for its current task.
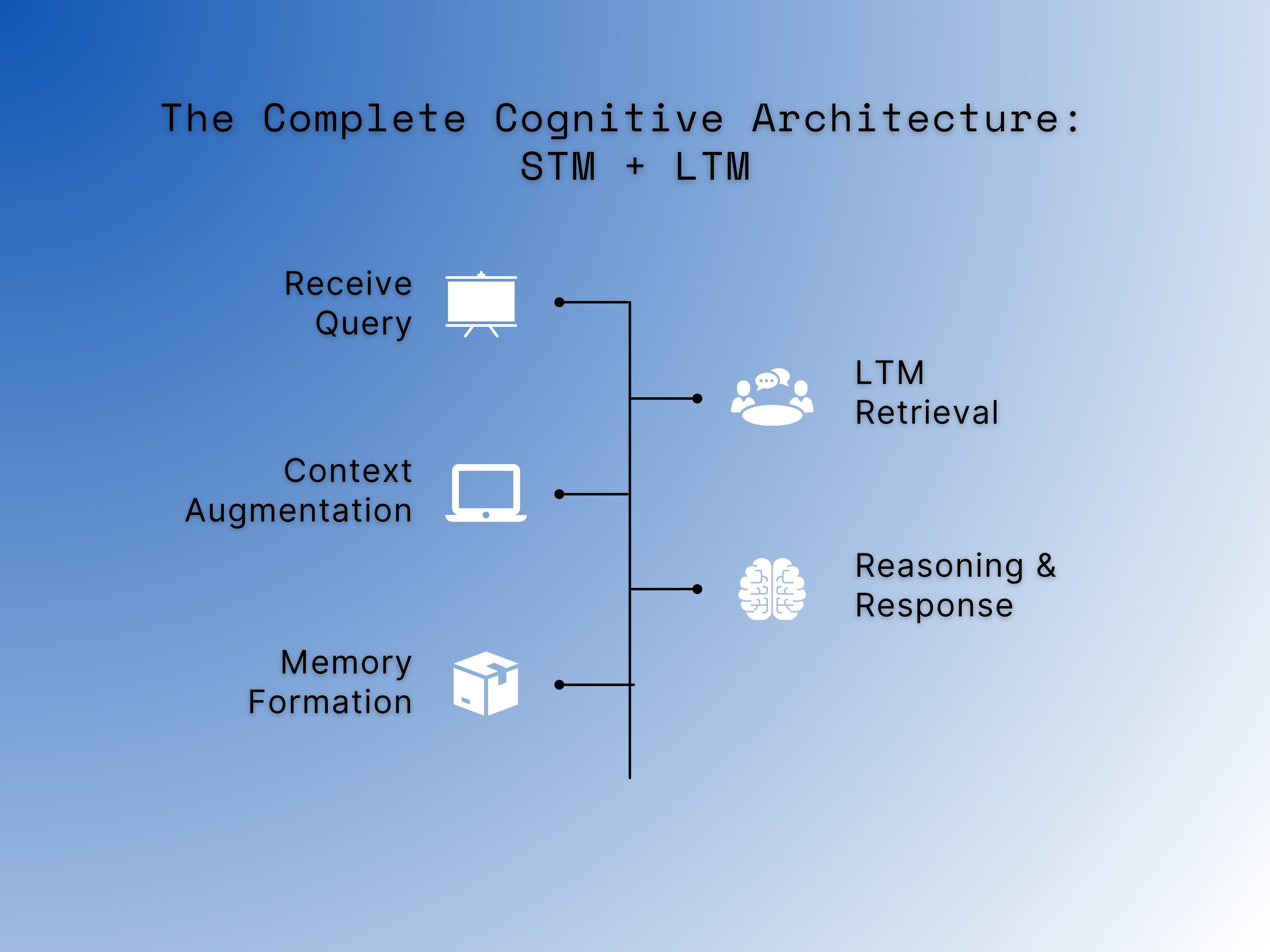
Workflow of a Memory-Enhanced Agent:
Receive Query: A user asks, “Can you suggest a good framework for my next AI project?”
LTM Retrieval: The agent queries its vector database: “Find all memories related to User X and ‘AI frameworks’.”
Context Augmentation: The retrieved memories (e.g., “User X is a beginner, previously asked about Python”) are added to the Short-Term Memory context.
Reasoning & Response: The LLM generates a response using both the current conversation (STM) and the personalized history (LTM): “Based on our chat last week, since you’re new to Python, I’d recommend starting with LangChain for its gentle learning curve.”
Memory Formation: After the interaction, a summary of key insights is generated and saved back to the Long-Term Memory.
This creates a virtuous cycle of learning and personalization.
Frequently Asked Questions (FAQ)
Q: Isn’t this just a fancy chat history?
No. Simple chat history is a linear log. A true LTM system involves semantic search and abstraction. It doesn’t just replay old messages; it identifies core preferences, patterns, and facts, and recalls them based on meaning, not just keywords. It’s the difference between searching your chat logs for “Python” and the system knowing you’re a beginner who prefers Python.
Q: How do you prevent the agent from retrieving irrelevant or outdated memories?
Through careful metadata filtering and relevance scoring. Memories are tagged with user IDs, timestamps, and topics. The retrieval step only pulls memories that are both semantically similar to the query and match the relevant filters (e.g., for the current user). Low-relevance scores can be discarded.
Q: What are the main technical challenges in building this?
A:
Hallucination in Memory Formation: If the agent incorrectly summarizes a conversation for LTM, it creates false “memories.”
Memory Contamination: Retrieving the wrong memory can lead to contextually inappropriate responses.
Scalability & Cost: Constantly reading from and writing to a vector database adds latency and operational cost.
Call to Action (CTA)
Building an agent with memory is what separates a compelling demo from a production-ready application that users form a lasting relationship with.
It’s the foundation for creating AI that feels less like a tool and more like a competent colleague.
This is just the first step in architecting truly intelligent systems.
At TheAgenticLearning.com, we dive deeper into the advanced patterns:
Designing multi-modal memory (text, audio, screenshots)
Implementing memory reflection and consolidation
Building secure, multi-user memory architectures
Subscribe to our newsletter for advanced guides, code blueprints, and expert insights that will help you build the next generation of Agentic AI.