
The Real Work in AI Services Is Making Data Legible
Everyone obsesses over the agent. In practice most of the engineering happens underneath it — turning an illegible enterprise data estate into something an agent can actually reason over. A technical look at how, and why it's the whole game.

Two years ago, growing a services business meant hiring people. The work was done by humans, so more work meant more humans, and the margins were whatever the labor math allowed. We are now building that same kind of business, enterprise system integration, to run mostly on agents instead of people. Engagements that used to take a team of twenty most of a year, we deliver with a small pod and a fleet of agents in weeks.
When people hear that, they assume the hard part is the agents. It isn't. The agents are the easy part. The hard part, the part that decides whether a project succeeds or quietly falls apart three weeks in, is everything underneath them: making the customer's data legible enough that an agent can reason over it without producing confident nonsense.
This is the least glamorous engineering I know of, and it is most of the job. Here is what it actually involves.
Semantic debt
Every enterprise is carrying what I have started calling semantic debt. It is like technical debt, except instead of shortcuts in the code, it is meaning that was never written down.
A schema tells you a table is called CUST_MASTER and has a column status_2 of type VARCHAR. It does not tell you that status_2 is the field people actually trust, that status was deprecated in 2017 but never dropped, that the values A/I/H mean active, inactive, and a third state nobody can define anymore, or that a quarter of the rows are test records from a migration that half-finished. None of that is in the database. It lives in the heads of people, some of whom have left.
Semantic debt shows up in a few consistent shapes:
Schema without semantics. You have column names and types, but not what they mean, which are authoritative, or how they relate.
Entity fragmentation. The same real-world thing is recorded several ways across systems that were bought rather than built, with no shared key. "Acme Corp," "ACME Corporation," and "Acme Inc." are three rows and one company.
Lineage loss. A number on a report exists, but how it was produced — which tables, which filters, which business rules — is gone. Two reports show different revenue and both are "right," because they define revenue differently and nobody wrote it down.
Silent contradiction. The data disagrees with itself in ways nothing flags: a fact row whose foreign key points at a dimension that does not exist, a date that is sometimes the order date and sometimes the ship date depending on the source.
An agent pointed at this does not see a mess. It sees confident inputs and produces confident outputs, and the outputs are wrong in ways that are expensive to catch later. Garbage that looks like an answer is worse than no answer.
Why the obvious approaches fail
The first instinct is to hand the model the raw schema: dump the DDL into the context, add a few sample rows, let it figure things out. This works in a demo and fails in production. The model invents joins that are not valid, picks the wrong grain, and chooses whichever of the three revenue definitions sounds most plausible. It has no way to know which status field is real, because that information is not in what you gave it.
Retrieval over the raw tables has the same problem one layer up. You can embed and search the data all you like; if the meaning was never captured, similarity search just retrieves the same ambiguity faster.
The thing the agent needs does not exist yet when you arrive. You have to build it.
Building the legibility layer
The legibility layer is an explicit, verified model of what the customer's data means. It is produced by a pipeline of six stages, with a human-in-the-loop wrapped around all of them.
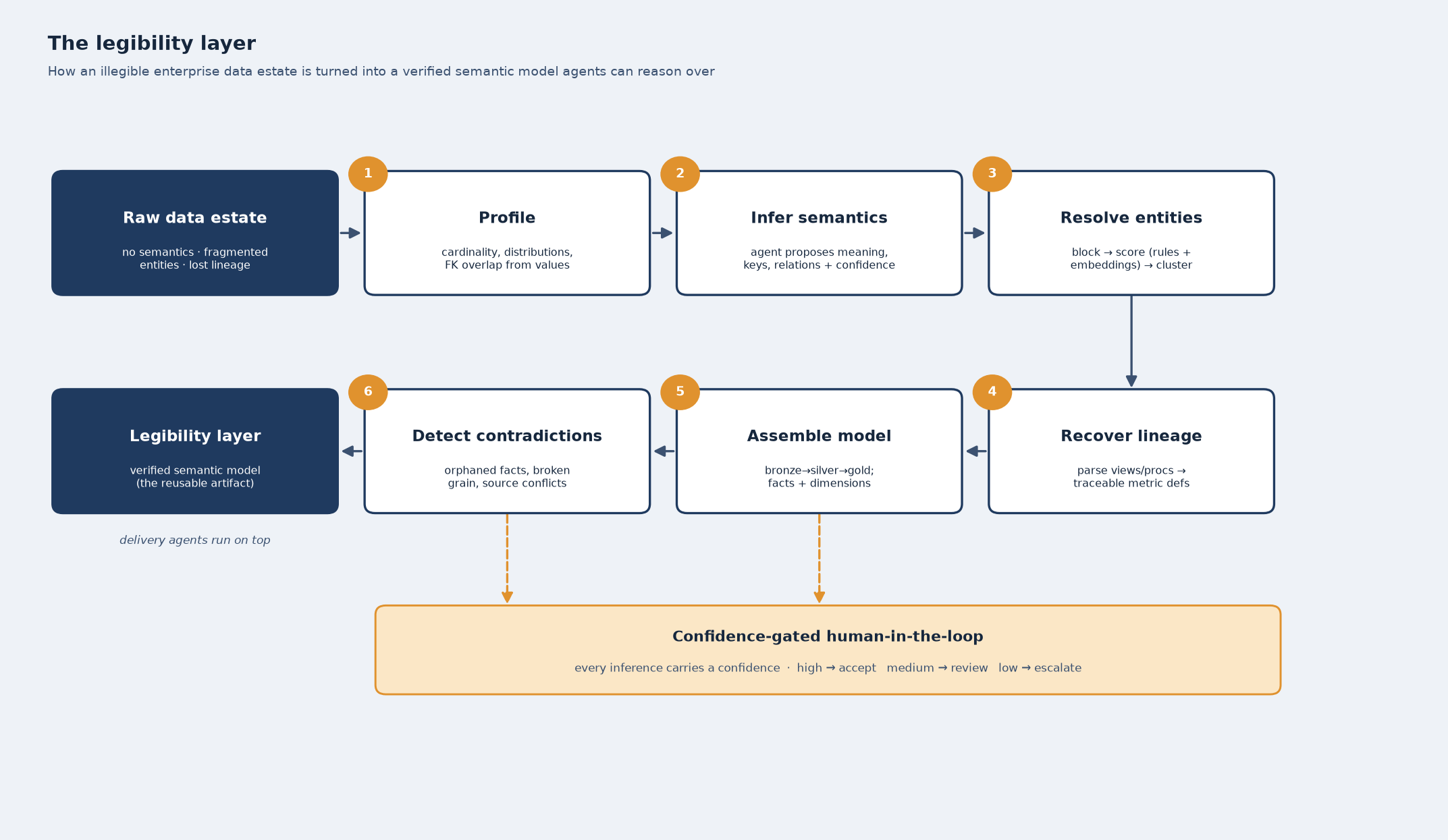
1. Profile before you interpret. Before a model is allowed an opinion about a column, we profile it directly against the data. For each column we compute cardinality and null rate, the distribution of values, and a format signature — do the values look like emails, ISO dates, currency, a short coded enum? We infer candidate primary keys from uniqueness, and candidate foreign keys from value containment: if 98% of orders.cust_ref values appear in cust_master.id, that is a join the declared schema never told you about. Statistics come first, because they ground everything downstream and catch the model the moment it starts to guess.
2. Infer meaning, then have a second model attack it. Each table and column goes to an agent along with its profile, a sample of real rows, and the names of its neighbors. The agent proposes what the field means, its semantic type, whether it is authoritative or a deprecated remnant, and how it relates to other tables — and it attaches a confidence to every claim. A second model runs as an adversarial check: same evidence, but its job is to falsify the first proposal. We route on the result in three bands. Above 0.9 with agreement auto-accepts. Between 0.7 and 0.9 is queued for human review. Below 0.7 escalates. The bands exist because a wrong semantic label here is not a local error; it is paid back, with interest, by everything built on top of it.
3. Resolve entities. The three-different-Acmes problem is its own discipline. Comparing every record to every other record is quadratic and hopeless at enterprise scale, so we block first — generate cheap candidate keys (a normalized name plus a postal code, say) so only plausibly-matching records are ever compared. Each candidate pair is then scored with a mix of deterministic rules and embedding similarity, the scores are thresholded, and the surviving links are clustered with union-find so that "Acme Corp ↔ ACME Corporation ↔ Acme Inc." collapse into one entity with one key. Pairs near the threshold — the genuinely ambiguous ones — go to a person. The output is a resolved entity the rest of the system can rely on.
4. Recover lineage. Where a metric is produced by transformations — SQL views, stored procedures, pipeline code — we parse them into syntax trees and build a column-level lineage graph: this report field comes from that view, which sums this column filtered by that flag. The business rules buried in the WHERE clause become part of the definition. "Revenue" stops being a word and becomes a specific, traceable computation everyone can point at and argue with.
5. Assemble the model. The verified pieces are assembled into a layered model. Raw landing data (bronze) is cleaned and conformed (silver) and then modeled (gold). The gold layer is shaped as a star schema: fact tables declared at an explicit grain, surrounded by conformed dimensions, so that a question like "revenue by region by quarter" has exactly one correct way to be answered. The grain is the contract. Most of the silent contradictions in enterprise reporting are really two numbers computed at two different grains and compared as if they were the same.
6. Detect what is broken. The same machinery that builds the model is run as a set of assertions against it: referential integrity (orphaned facts pointing at missing dimensions), grain violations (a "unique" business key that is duplicated), cross-source reconciliation (the same metric from two systems, and the delta between them), and temporal anomalies. A lot of the value we deliver in the first weeks of an engagement is simply telling a customer the truth about their own data, with the specific offending rows attached.
At the end of this you have something the customer never had: a written, verified account of what their data means. That artifact is the product. The agents that do the actual delivery work — migration, validation, answering questions, monitoring for drift — all stand on top of it.
Why we let agents do it, and why we watch them
Two things make agents well-suited to this. The work is enormous and repetitive, far too much for a human team to do by hand across thousands of columns and hundreds of tables. And it is exactly the judgment-under-ambiguity that language models are good at, given enough grounding.
Two things make it dangerous. Models are confident when they are wrong, and this is precisely the place where a wrong answer gets baked into everything downstream. So the agents never run unsupervised. Every inference is grounded in real profiles and samples rather than the model's prior, every output carries a confidence, a second model checks the first, and a human owns the thresholds where the system stops and asks. The goal is not full autonomy. It is a system that does the overwhelming bulk of the work and knows the exact boundary of what it is sure about — and widens that boundary as it earns trust.
Why this is the whole game
A services business can run on software not because the agents are clever, but because this layer, once built, is leverage. The semantic model is reusable. The entity resolution compounds. The lineage stays recovered. The next engagement at a similar customer, on a similar source system, starts further along than the last one did. The labor you would have spent on twenty people for six months collapses into the work of building and verifying this artifact once, after which everything you deliver runs on it.
That is why services as software is an engineering story and not a margin story. The margin is a consequence. The cause is whether you can take an illegible enterprise data estate and make it legible faster and more reliably than a room full of consultants could.
This is the first piece of the playbook. The next ones go up the stack: the delivery agents that run on top of this layer, how confidence routing lets you sell an outcome instead of hours, and how a small pod of people is organized around a fleet of agents. The foundation comes first, because nothing above it works without it.
— Nikhil
The best description of the Ai services opportunity and the business model that works!